NYU HPC
Drew Dimmery
February 19, 2014
Structure of this Talk
- "Basic" R optimization
- Delve into some necessary UNIX magic
- Talk about some basics of HPC
- Specifics of NYU's HPC
- Examples
- Please interrupt with questions / comments / insults!
R optimization
- I will speak (briefly) about two forms of optimization:
- Compilation
- Multi-process (there is no multi-threading)
Travelling example
- For the next bit, I'm going to create an example which will travel with us (for the sake of benchmarks)
- We're going to consider the following task:
- Given a vector of 5000 values, take the mean of the first 25 values for each of 100 equally sized groups.
set.seed(20140219)
Y <- rnorm(5000, rep(c(1, 5, 10, 25, 50), rep(1000, 5)))
Y <- Y[sample(5000)]
G <- rep(1:100, rep(50, 100))
dofor <- function(x, y = Y, g = G) {
for (i in unique(g)) mean(y[g == i])
}
dotapp <- function(x, y = Y, g = G) {
tapply(y, g, function(z) mean(z))
}
repfn <- function(f, n = 100, cmp = FALSE) {
tm0 <- Sys.time()
if (cmp == TRUE)
f <- cmpfun(f)
replicate(n, f(0))
tm1 <- Sys.time()
(tm1 - tm0)/n
}
bench <- c(forLoop = repfn(dofor), tapply = repfn(dotapp))
bench/min(bench)## forLoop tapply
## 3.167 1.000Compiling R code
- For a while now, R has shipped with the
compilerpackage pre-installed. - This allows us to (sometimes) speed things up.
- Compiling is "slow", but running compiled code is "fast".
- (But remember that many functions in R are already compiled)
- Compile a function with
cmpfun
require(compiler)
bench <- c(bench,
forComp=repfn(dofor,cmp=TRUE),
forPreComp=repfn(cmpfun(dofor)),
tappComp=repfn(dotapp,cmp=TRUE)
)
bench/min(bench)## forLoop tapply forComp forPreComp tappComp
## 3.167 1.000 3.132 3.081 1.032Compilation Speedup
- No huge speedups in this example from compiling.
- Speedups will come when the computational burden is heavy (rather than just in subsetting things as shown here).
- But large improvements from "vectorization".
- Most common functions (matrix math, etc) are already in compiled C++/FORTRAN, so gains on simple functions will be limited.
- Adding in heavier computations gives more of an advantage to compiled functions:
fun <- function(x, y = Y, g = G) {
a <- 1:5000 * g
b <- y - 32
ab <- tcrossprod(a, b)
for (i in 1:5000) {
ab[i, i] <- g[i]%%3
}
for (i in 1:5000) {
ab[i, 1] <- a[i] - b[i]
ab[1, i] <- b[i] - a[i]
}
}
bench2 <- c(repfn(fun), repfn(fun, cmp = TRUE))
bench2/min(bench2)## [1] 1.243 1.000JIT Compiling
- What in the hell is a jit?
- Just-in-time compiling
- It will compile your functions just before you use them for the first time.
- Each subsequent execution will be faster.
- Chrome does this with javascript.
- This is basically the same behavior as we forced automatically in
repfn. - You can also tell R to automatically compile functions in packages when you load a package.
- To do this, put the following in your
.Renvironfile in your home directory.
R_COMPILE_PKGS=TRUE
R_ENABLE_JIT=3Multi-process R
- R does not use the 2/4/8/16 cores on your computer unless you make it.
- A single R process can only use a single core.
- So we have to start up multiple R processes, and then let them talk to each other.
- Simplest way to do this is with the
snowlibrary. - Stands for Simple Network of Workstations
require(snow)
cl <- makeCluster(4)
dotappClus <- function(x) {
parLapply(cl, split(Y, G), mean)
}
repfnClus <- function(f, n = 100) {
tm0 <- Sys.time()
parSapply(cl, integer(n), f, y = Y, g = G)
tm1 <- Sys.time()
(tm1 - tm0)/n
}
bench <- c(bench, tappClus1 = repfn(dotappClus), tappClus2 = repfnClus(dotapp),
forClus = repfnClus(dofor))
stopCluster(cl)
bench/min(bench)## forLoop tapply forComp forPreComp tappComp tappClus1
## 6.635 2.095 6.561 6.454 2.162 2.387
## tappClus2 forClus
## 1.000 2.800More multiprocess
- Four processes, but only a doubling in speed??!
- Yes, expect this. There is overhead associated with parallelization.
- You'll do better when the numbers returned from your function are small, but the processing power needed to get them is large.
- Bootstrapping, for instance, will greatly benefit from parallelization.
- Warning: pseudorandom number generation across cores will be correlated.
- There are other, more user friendly (to you, maybe) tools for parallelization.
- Examples:
snowfall,doParallel
require(doParallel, quietly = TRUE)
cl <- makeCluster(4)
registerDoParallel(cl)
invisible({
t0 <- Sys.time()
foreach(i = 1:100) %dopar% dotapp(0)
t1 <- Sys.time()
})
stopCluster(cl)
bench <- c(bench, tappForEach = (t1 - t0)/100)
bench/min(bench)## forLoop tapply forComp forPreComp tappComp tappClus1
## 6.635 2.095 6.561 6.454 2.162 2.387
## tappClus2 forClus tappForEach
## 1.000 2.800 2.033Multiprocess JAGS/stan
Conceptually, it's trivial to parallelize chains in MCMC.
For JAGS, there is a package available,
dclone(for data cloning) that includes helpful functions to run chains in parallel.Check the documentation, but it looks pretty easy.
parJagsModelandparCodaSamplesThis package should take care of instantiating each pRNG with sufficiently different seeds.
For stan, you don't get much help. Do your parallelism in such a way that you get a list of
stanfitobjects, then combine them with the helper functionsflist2stanfit.So you could do something like:
parSapply(cl, function(i) stan(fit = f1, seed = seed, chains = 1, chain_id = i,
refresh = -1))There are examples in the R documentation for
sflist2stanfit, so check that out.By iterating the chainid, and having a consistent seed, stan should ensure that you get different pRNG sequences.
Basic *NIX files and folders
- User specific folders will have my NETID (ddd281), replace with your own.
- Folders are notated as
\home\ddd281\bin(my "home" directory) - This is equivalent to
~\bin - We navigate between folders with
cd \home\ddd281 - Create a new folder with
mkdir \home\ddd281\FolderName - To see what is in a directory, use
ls -l ~\bin - Omitting a folder argument means list the files in the current folder.
- On the HPC, you also have some other folders you should know.
\home\ddd281- 5GB limit per user.- Put your source code / scripts / executables here.
\scratch\ddd281- This is the "working directory" for running jobs. It has a 5TB limit per user.- Inactive files older than 30 days will be deleted.
- NO BACKUPS. Don't leave mission critical work here.
\archive\ddd281- This is longer-term storage. It is backed up, and begins with an allocation of 2TB/user. Faculty sponsors can request more.
Some basic file commands
mv src dstto move filesrctodst(can also function as a "rename")cp src dstto copy filesrctodstrm srcto remove (delete)src- Make them recursive by adding the
-rflag to them. - I use
rsyncto move files to and from the cluster, but you can also use WinSCP or gFTP or similar program. - Basic syntax is
rsync -azvr src dst- There are some funky things with trailing slashes. (read the manpage) - These programs will need to have the
hpctunnelactive, first, and then you can log onto the individual clusters to transfer files.
Standard Input / Output
- *NIX is based around simple programs doing simple things.
- This leads to the standard input / output paradigm.
- Most tools will "put" output directly in the terminal.
- But we can redirect output that WOULD have gone to the terminal.
- For instance,
ls -l | wc -llists the files in a directory, and then sends that output to the next command. wc -lcounts the lines in the input. So the combined command counts the number of files in a folder.- This behavior is very important to understand.
- We can also choose to dump output to a file, as in
ls -l > out.file - And we can append to a file with
ls -l | wc -l >> out.file - Sometimes commands will give us errors, and we might like to redirect those to a log file too.
- We could do this with
&>or&>>(to redirect both stdout and stderr) - If we only wanted stderr (stdout), then use
2>(1>) - This will be useful to us later for log files (and general scripting).
Basic file editing
- Edit a file on the command line with something like
vim,nano,emacs, etc (personal preference, butvimis the best) - We can "edit" files via command line using the redirecting we saw before.
echo "This is a line ot text." > out.file- We can use the stream editor (
sed) to do simple search and replace using regular expressions. cat out.file | sed "s/ot /of /" > out.filefixes our typo.- And these sorts of things can be strung together for power and flexibility.
- In fact, they can be placed in a shell script.
Shell Scripts
- We create a shell script by creating a plaintext file.
- Can name it anything, but typically use extension
.sh - Put
#!\usr\bin\env bashon the first line - Then each line is a command to execute on the shell.
- You then make the script executable with
chmod +x scriptname.sh - Run it with
./scriptname.shorsh scriptname.sh - It's easy to pass in command line arguments, too.
- Refer to them in the script as
$1(for the 1st argument) and so on. - Variables can be saved in the script with
VAR=24and recalled with$VAR - Some variables are "global", in the sense that they're pre-existing once you instantiate a shell.
$PATHis your "search path" which lists (in order) where the shell will search for executable files.- Add a new folder to the path with
export PATH=/home/ddd281/bin:$PATH
Example
nyuhpc_update.sh
#! /usr/bin/env bash
set -e
if [ "`ps aux |grep hpctunnel|wc -l`" -lt "2" ] ; then
echo "Need to have HPC's SSH tunnel active. Run ssh hpctunnel"
exit 0;
fi
if [ "$1" != "pdfs" ]; then
rsync -avzr --exclude '*.pdf' --delete cpp/ bowery:~/ocr_files/
exit 0;
fi
rsync -azvr --delete cpp/ bowery:~/ocr_files/
exit 0;Extra Resources
- Bash is Turing complete, so you can do "anything".
- It does some weird things, though (look into the differences in quotation marks in bash)
- There are a ton more places to look for inormation on shell scripts.
- Bash Beginner's Guide
- Advanced Bash-Scripting Guide
- Bash Shell Scripting Wikibook
- And many many more
Now onto HPC!
- NYU HPC is a shared resource.
- This means that we don't just "run" a program.
- We place a request to run a program in the queue. (I'll call it a "job")
- There are multiple clusters with different capacities.
- On each cluster, there are multiple queues with different restrictions.
- In practice, I've never seen the available resources saturated, so jobs run immediately.
- We control everything via command line.
- You may have to do special preparations to get things from your computer to work on the HPC.
- For instance, if a program is compiled, you'll (probably) have to recompile on the HPC.
Accessing the HPC
- First, you need a faculty sponsor (Hi, Neal!)
- Then, ask for access via http://hpc.nyu.edu/accounts
- Next, make sure you have SSH. If you have a Mac or Linux computer, you're good. For Windows, get PuTTy
- If you're on Mac or Linux, add the code from the following slide to your
~/.ssh/configfile (create if it doesn't exit) - In general, the process is to connect to the login machine ("bastion"), and then connect from there to the cluster you want to use.
- On Mac or Linux (with the tunnel config), simply open a terminal, run
ssh hpctunneland then login. Then, in a new terminal, you can connect to the cluster you want withssh usq,ssh bowery,ssh cardiac1 - On Windows, just log into bastion by connecting to
ddd281@hpc.es.its.nyu.edu, login, and then you can simplyssh usq(or whichever cluster)
SSH Tunneling Config
Host hpctunnel
HostName hpc.es.its.nyu.edu
LocalForward 8020 usq.es.its.nyu.edu:22
LocalForward 8021 bowery.es.its.nyu.edu:22
LocalForward 8022 cardiac1.es.its.nyu.edu:22
User NetID
Host usq
HostName localhost
Port 8020
ForwardX11 yes
User NetID
Host bowery
HostName localhost
Port 8021
ForwardX11 yes
User NetID
Host cardiac1
HostName localhost
Port 8022
ForwardX11 yes
User NetIDChoosing a Cluster
- Bowery
- Union Square
- Cardiac
- BuTinah (NYU-AD)
- Teraflops are a measure of speed (FLOPS = floating point operations / second)
- My MacBook Air is something like 10-15 GFlops to give a frame of reference.
- If you're using more than 4-8GB or so of RAM, you will need to check to see how much memory is allocated to each node.
- If you need more than that allocation, you'll need to request additional nodes.
- Generally: before you use a particular queue, check to make sure there isn't anything special you need to do.
Bowery
- 230 compute nodes
- 2528 cores
- 8.95 TB RAM
- 28.23 TFlops
- Queues:
- p12 - max 12hrs/6 jobs - up to 288(576) CPU cores
- p48 - max 48hrs/exclusive node - up to 64(128) CPU cores
- s48 - max 48hrs/500 jobs - up to 36(72) CPU cores
- interactive - max 4hrs/2 jobs - up to 32 CPU cores
- bigmem - max 48hrs/exclusive node - up to 96(192) CPU cores
- cuda - max 48hrs/exclusive node
- Software:
- R (3.0.1)
- Matlab
- Mathematica
- Stata
- Python
Union Square
- 60 compute nodes
- 584 cores
- 1.5 TB RAM
- 4.47 TFlops
- Queues:
- ser2 - max 48hrs - up to 64(128) CPU cores
- serlong - max 96hrs - up to 32(64) CPU cores
- interactive - max 4hrs/2 jobs
- Software:
- R (only up to 2.9.2)
- Matlab
- Mathematica
- JAGS
- Stata (parallel)
- Python (only 2.x.x)
Cardiac
- 75% of this cluster is devoted to research group aimed at constructing a functional computer model of the beating human heart.
- 25% (or more if there are idle resources) are available to the rest of us.
- 62 compute nodes
- 1264 cores
- 2.47 TB RAM
- 9.12 TFlops
- Queues:
- p12 - max 12hrs/exclusive node - up to 192(384) CPU cores
- p48 - max 48hrs/exclusive node - up to 96(192) CPU cores
- ser2 - max 48hrs - up to 72(144) CPU cores
- serlong - max 96hrs - up to 32(64) CPU cores
- interactive - max 4hrs
- Software:
- R (3.0.1)
- Matlab
- Mathematica
- JAGS
BuTinah
- 537 compute nodes
- 6464 cores
- 28 TB RAM
- 69.36 TFlops
- Queues:
- p12 - max 12hrs - up to 288(576) CPU cores
- p48 - max 48hrs - up to 64(128) CPU cores
- s48 - max 48hrs - up to 12 CPU cores per node
- s96 - max 96hrs - up to 12 CPU cores per node
- interactive - max 4hrs
- bigmem - max 48hrs - up to 12 CPU cores per node
- gpu - max 48hrs
- route - none
- Software:
- Matlab
- Mathematica
- ???
Using the HPC
- Using the HPC is as simple as creating a shell script which runs the things you want run.
- We can run an R script from the command line with
Rscript filename.R - And we can use Stata's batch mode with
stata -b do filenameorstata < filename.do > filename.log - This will save output to a log file of "filename.log". Things you save manually during execution will be saved as normal.
- StataMP is on one of the clusters, so enable parallelism with the line
set processors Xwhere X is the number of cores to use. - Running personally compiled programs is very easy, and is simply
./my_program - Of course, it isn't quite this simple, as our shell scripts have to have extra information for the queue scheduler.
HPC Scripts
- For simple tasks (for instance, that take less than 4 hours, and don't require many processing cores), we can use interactive mode.
qsub -I -q interactive -l nodes=1:ppn=8,walltime=04:00:00- I'll assume at this point that you have a shell script running your R program or whatnot.
- Turning it into a script ready to run on the HPC is as simple as adding a header like the following:
#PBS -V
#PBS -S /bin/bash
#PBS -N ocr-2014-02-19
#PBS -l nodes=1:ppn=1,walltime=10:00:00
#PBS -l mem=1GB
#PBS -q s48
#PBS -M ddd281@nyu.edu
#PBS -m bea
#PBS -w /scratch/ddd281/ocr_wd/
#PBS -e localhost:${PBS_O_WORKDIR}/pbs_files/${PBS_JOBNAME}.e${PBS_JOBID}
#PBS -o localhost:${PBS_O_WORKDIR}/pbs_files/${PBS_JOBNAME}.o${PBS_JOBID}PBS options
- Let's go through line by line what this means.
#PBS -V- exports environment variables from current session to the job's sessionPBS -S /bin/bash- which shell to use. No need to change this.#PBS -N ocr-2014-02-19- a name for the job. This will be used in emails, and in naming some logfiles.#PBS -l nodes=1:ppn=1,walltime=10:00:00nodes=1- tells the scheduler how many nodes to allocate to the jobppn=1- how many processors per node?walltime=10:00:00- how much time to allocate to this job (and NO longer)
#PBS -l mem=1GB- how much memory to allocate to this job (and NO longer)#PBS -q s48- which queue should this job be placed in?#PBS -M ddd281@nyu.edu- NYU email#PBS -m bea- email me on begin, aborts, ends#PBS -w /scratch/ddd281/ocr_wd/- sets the working directory for the job#PBS -e localhost:${PBS_O_WORKDIR}/pbs_files/${PBS_JOBNAME}.e${PBS_JOBID}- location to redirect stderr#PBS -o localhost:${PBS_O_WORKDIR}/pbs_files/${PBS_JOBNAME}.o${PBS_JOBID}- location to redirect stdout- Read
man qsubfor much more information on options.
Managing the Queue
qsubto submit a job (pbs script)showq | grep ddd281to view your jobs in the queueqdel 1234to delete job number 1234qstat 1234to see status report on job 1234
Enabling Software
- Not all software installed on the cluster is always available.
- Often, you will need to load the appropriate module, first.
- For instance, if you're on Bowery, to load R-3.0.1:
module avail- Find the appropriate module name,
r/intel/3.0.1 module show rfor more info (for instance, where binaries are stored, etc)- Load it,
module load r/intel/3.0.1 - This would need to go in your pbs script before you try to run an R script.
- (Similarly for Stata)
- One hiccup, is you need to ensure that the
modulecommand is available:source /etc/profile.d/env-modules.sh - If there's time, I'll talk about compiling software at the end.
Example Time
- I find it is often useful to put placeholders in the raw pbs file and then run a helper script to set things up.
- For instance, if I am using cross-validation to determine the number of topics to use in LDA.
- I might parallelize this task by submitting a single job for each number of topics.
- This will take a pretty significant chunk of time, as I must estimate the model k times (for k-fold CV).
- This is an embarrassingly parallel task. Meaning that the computation at different numbers of topics are completely independent.
- Then I can easily write an R script which will take two command line arguments (min/max number of topics) and perform the k-fold CV to get an estimate of the perplexity of the model at each number of topics within those bounds.
- It outputs a datafile containing only a single matrix summarizing the output.
- This script is on the next page.
LDA CV Script
hpc.R
args <- commandArgs(trailingOnly = TRUE)
if(length(args)!=2) stop(paste0("Not the right number of arguments!",args))
args <- as.double(args)
load("s_africa_data.Rdata")
require(cvTools)
require(topicmodels)
cvLDA <- function(Ntopics,K=5) {
folds<-cvFolds(nrow(dtm),K,1)
perplex <- rep(NA,K)
llk <- rep(NA,K)
for(i in unique(folds$which)){
which.test <- folds$subsets[folds$which==i]
which.train <- {1:nrow(dtm)}[-which.test]
dtm.train <- dtm[which.train,]
dtm.test <- dtm[which.test,]
lda.fit <- LDA(dtm.train,Ntopics)
perplex[i] <- perplexity(lda.fit,dtm.test)
llk[i] <- logLik(lda.fit)
}
perplex <- mean(perplex)
perpSD <- sd(perplex)
llk <- mean(llk)
llkSD <- sd(llk)
return(c(K=Ntopics,perplexity=perplex,perpSD=perpSD,logLik=llk,logLikSD=llkSD))
}
Topics.to.Est <- seq(args[1],args[2])
cv.out <- t(sapply(Topics.to.Est,cvLDA))
name<-paste0("cv.out.",min(Topics.to.Est),".",max(Topics.to.Est))
assign(name,cv.out)
save(list=name,file=paste0(name,".Rdata"))And accompanying PBS Script
- Note, here, that I actually had to install my own R (because a package I needed [topicmodels] wasn't available in 3.0.1)
- I have to load the gsl module because topicmodels must be built from source in Linux, and it relies on the GNU Scientific Library dynamically (meaning that the library must be independently installed and available on the computer)
- But note as well that the parameters passed to R aren't right. I don't want to estimate a model with INSERTMIN topics.
- I use a helper script to set things up for me.
PBS Script
ldacv.pbs
#!/bin/bash
#PBS -V
#PBS -S /bin/bash
#PBS -N ldacv-INSERTMIN-INSERTMAX
#PBS -l nodes=1:ppn=1,walltime=12:00:00
#PBS -l mem=8GB
#PBS -q s48
#PBS -M ddd281@nyu.edu
#PBS -m bea
#PBS -e localhost:${PBS_O_WORKDIR}/pbs_files/${PBS_JOBNAME}.e${PBS_JOBID}
#PBS -o localhost:${PBS_O_WORKDIR}/pbs_files/${PBS_JOBNAME}.o${PBS_JOBID}
set -e
OLDDIR=`pwd`
cd /scratch/ddd281/ldacv
module load gsl/intel/1.15
/home/ddd281/local/bin/Rscript --vanilla hpc.R INSERTMIN INSERTMAX
cd $OLDDIR
exit 0;Helper Script
- This file is saved as the shell script
start_ldacv.sh - Now, all I have to do to submit a job is to type
./start_ldacv.sh 50 50 - That would perform CV on a 50 topic model.
- I could also submit a job for a range of models with
./start_ldacv.sh 10 13
#!/bin/bash
set -e
cat ldacv.pbs | sed "s/INSERTMIN/$1/g" | sed "s/INSERTMAX/$2/g" > ldacv.${1}-${2}.pbs
qsub ldacv.${1}-${2}.pbs
rm ldacv.${1}-${2}.pbsCombine estimates
- And then to take all of these small data files and combine them, I can use a simple R script.
- This will collect all the data files (of the format I created) in the current directory and put them into a single new matrix.
files <- dir()
files <- files[grep("cv.out", files)]
cv.out <- NULL
for (f in files) {
load(f)
vr <- strsplit(f, ".", fixed = TRUE)[[1]]
vr <- paste(vr[-length(vr)], collapse = ".")
cv.out <- rbind(cv.out, get(vr))
rm(list = vr)
}
cv.out <- cv.out[order(cv.out[, "K"]), ]
save(cv.out, file = "ldacv_all.Rdata")Output
- All that work, and basically all I got was this graph:
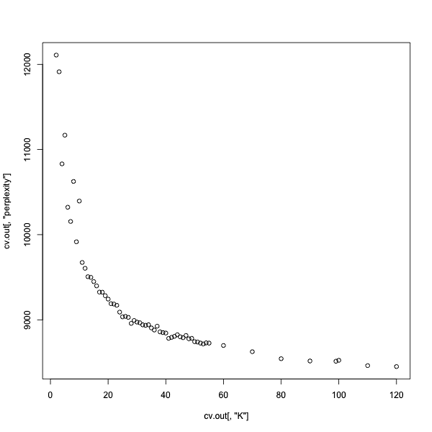
mapReduce!
- Aaaand we've independently rediscovered mapReduce.
- The map portion was in dividing my CV procedure up by number of topics.
- The reduce portion was in a) performing CV on each and getting summaries and b) merging the datasets together.
- But things are embarrassingly parallel, so it was much simpler to just treat all the jobs completely independently (no communication necessary)
- Using actual parallelism for this (ie via
snow) would only be more complicated and error prone
Courtesy
- Since the HPC is a shared resource, we should try to be courteous in how we use it.
- Use an interactive compute session when you want to compile something or test something.
- Don't just do it on the login node - this will slow things down for everyone.
- If you're submitting a bunch of little jobs (let's define "little" as "less than an hour"), then consider running a "batch" job:
#PBS -l nodes=<N/12>:ppn=12
...
cd directory_for_job1
mpiexec -comm none -n 1 $executable arguments_for_job1 > output 2> error &
...
cd directory_for_jobN
mpiexec -comm none -n 1 $executable arguments_for_jobN > output 2> error &
wait- This won't make the scheduler work quite so hard.
- Always put
set -eat the start of shell scripts! This will make it quit immediately upon encountering an error.
Compiling R
- First, I'll just talk about how to compile R, because I imagine this is the most common thing you'll need to compile.
- Typically, compilation is accomplished with the following:
./configuremake && make install - But this would install systemwide, which we can't do on the HPC.
- So we have to add
--prefix=/home/ddd281/localtoconfigure - We can then do
make && make installas normal. This will install R to the appropriate directory. - This should work, but if not, you may need to ensure that the compiler is installed.
module load gcc/4.7.3(on bowery, versions may be different, so checkmodule avail)- You can then either add
\home\ddd281\local\binto your PATH, or you can just call R with\home\ddd281\local\bin\Rscript
Compiling your own code
- Compiling your own code can be a real pain.
- If you need to link it to a library, you'll need to load the appropriate module, or install the library to your home directory.
- NYU recommends using the Intel Compiler suite (which you'll need to load)
module load intel/11.1.046 - And then compile with
icc/icpc/ etc - You probably also want to use some optimization flags. NYU provides the example of:
-O2 -fPIC -align -Zp8 -axP -unroll -xP -ip - I found that I had to add the flag
-shared-intelto get my C++ to compile properly. - This whole process is a minefield, though. Be prepared to use Google.